
介紹
數據倉庫 (DW) 是現代企業的關鍵組成部分,通過將來自各種來源的資訊整合到一個一致且結構化的存儲庫中,實現數據驅動的決策。隨著基於雲的解決方案、大數據技術和即時分析變得越來越普遍,構建數據倉庫的最佳實踐已經發生了重大變化。本指南概述了設計、開發和維護數據倉庫的最佳實踐,包括現代進步和行業特定的使用案例。
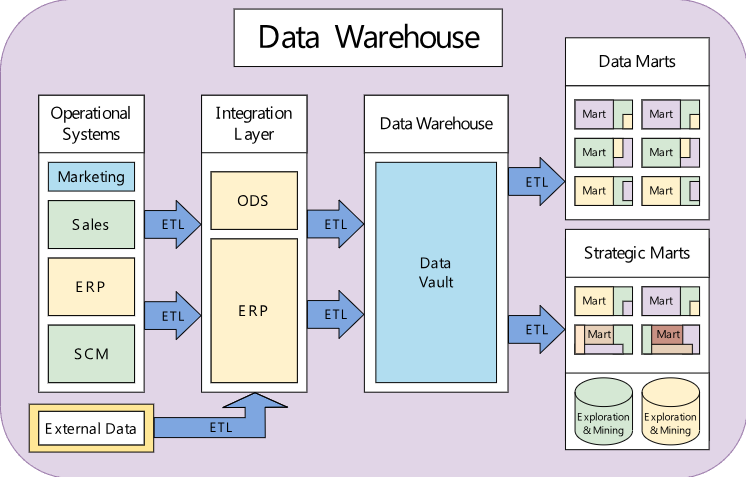
1.了解數據倉庫架構
資料主目錄通常設計有以下層:
- 源層:從作系統、IoT 設備、外部 API 等收集數據。
- 暫存層:用於 ETL 處理的臨時存儲區域。
- 集成層:數據以結構化格式進行轉換、清理和存儲。
- 表示層:針對分析和報告進行了優化。
數據倉庫架構的類型
- 傳統的本地數據倉庫
- 使用 Oracle、SQL Server 或 IBM Db2 等關係資料庫。
- 適用於對數據治理有嚴格要求的行業。
- 基於雲的數據倉庫
- 示例:Amazon Redshift、Google BigQuery、Snowflake。
- 提供可擴充性、彈性和成本效益。
- 混合數據倉庫
-
- 結合本地存儲和雲存儲以實現靈活性。
- 供過渡到雲同時維護舊系統的組織使用。
使用案例:一家全球零售公司將 Snowflake 用於其雲數據倉庫,同時維護本地 PostgreSQL 系統以確保合規性。
__________________________________________________________________________________________________________________
2. 數據倉庫設計的最佳實踐
2.1 定義明確的業務目標
- 使數據倉庫目標與業務需求保持一致。
- 確定關鍵利益相關者並確保滿足他們的報告需求。
示例:一家金融機構需要一個數據倉庫來實時跟蹤欺詐檢測模式。
2.2 選擇正確的數據建模方法
- 星型架構:簡單且針對快速查詢進行了優化。
- Snowflake 架構:針對複雜的分析處理進行標準化。
- Data Vault:可擴展且適應性強,適用於大規模實施。
使用案例:醫療保健供應商採用數據保險庫模型來集成多家醫院的患者記錄。
2.3 確保數據品質和一致性
- 實施數據清理和重複數據刪除流程。
- 使用數據治理框架來實施標準。
示例: 物流公司應用即時數據驗證規則來確保貨物跟蹤準確。
2.4 優化 ETL 和 ELT 流程
- ETL(提取、轉換、載入)是傳統的,但可能很慢。
- ELT(提取、載入、轉換)是現代的,可與基於雲的數據湖完美配合。
示例:一家媒體公司使用Google BigQuery 切換到ELT,將數據處理時間縮短了40%。
2.5 實施數據安全性和合規性
- 加密靜態和傳輸中的敏感數據。
- 實施基於角色的訪問控制 (RBAC)。
- 確保遵守GDPR、HIPAA或行業特定法規。
用例:一家銀行在將客戶 PII 數據存儲到倉庫之前對其進行匿名化處理,從而確保 GDPR 合規性。
__________________________________________________________________________________________________________________
3. 性能優化技術
3.1 索引和分區
- 使用列式存儲加快查詢執行速度。
- 為分散式工作負載實施分片。
示例:一家電信公司按區域對呼叫記錄進行分區,以便更快地檢索。
3.2 數據緩存和物化檢視
- 對經常訪問的報表使用緩存。
- 實施具體化檢視以預先計算複雜查詢。
使用案例:一家電子商務公司緩存即時產品推薦,以提供無縫的用戶體驗。
3.3 數據倉庫自動化
- 使用 AI 驅動的 ETL 工具,如 Talend 或 Apache NiFi。
- 實施工作流自動化以減少人工干預。
示例:一家製造公司使用 Apache Airflow 自動化日常 ETL 管道,從而提高效率。
__________________________________________________________________________________________________________________
4. 數據倉庫的現代趨勢
4.1雲原生數據倉庫
- AWS Redshift、Azure Synapse 和 Google BigQuery 在市場上佔據主導地位。
- 提供可擴充性、自動備份和成本節約。
4.2 即時和流式分析
- Flink 支援實時數據攝取。
- 適用於欺詐檢測、IoT 分析和客戶行為監控。
使用案例:一家拼車公司分析實時駕駛員和乘客數據以進行動態定價調整。
4.3 AI 和機器學習集成
- 數據倉庫現在支援用於預測分析的ML模型。
- 示例:Snowflake ML、BigQuery ML、AWS SageMaker。
示例:一家銀行在其數據倉庫中集成 ML 以預測貸款違約風險。
4.4 數據湖倉一體架構
- 將數據湖的可擴充性與數據倉庫的結構化查詢相結合。
- 示例:Databricks、Delta Lake 和 Apache Iceberg。
使用案例:一家製藥公司採用數據湖倉一體,通過海量數據集更快地發現藥物。
__________________________________________________________________________________________________________________
5. 主要挑戰和解決方案
5.1 數據孤島和集成問題
- 使用數據虛擬化提供統一視圖,而無需物理行動數據。
5.2 管理成本
- 使用冷熱數據分層優化存儲。
- 為 Cloud Warehouse 實施基於使用量的定價模型。
5.3 變更管理和用戶採用
- 為 BI 和分析團隊提供持續培訓。
- 使用Tableau或Power BI等自助式BI工具更輕鬆地採用。
__________________________________________________________________________________________________________________
6. 構建資料倉庫的步驟(時間:12-18 個月)
第 1 階段:規劃(0-3個月)
- 定義業務目標和範圍。
- 選擇適當的體系結構和技術。
- 確定關鍵數據來源。
第 2 階段:數據建模和 ETL 設計(3-6 個月)
- 設計架構(Star、Snowflake 或 Data Vault)。
- 開發用於數據攝取的 ETL 管道。
第 3 階段:開發和測試(6-12 個月)
- 構建數據倉庫基礎設施。
- 實施安全措施和合規性策略。
- 進行使用者驗收測試 (UAT)。
第 4 階段:部署和優化(12-18 個月)
- 在生產環境中部署數據倉庫。
- 監控性能並優化查詢。
- 對最終用戶進行報告工具培訓。
結論
構建數據倉庫需要精心規劃的策略、強大的架構和持續優化。隨著組織採用雲計算、即時分析和 AI 集成,現代數據倉庫必須具有可擴充性、安全性和高效性。遵循這些最佳實踐將確保成功實施,使企業能夠利用數據來做出更好的決策和獲得競爭優勢。
通過遵循本指南中概述的戰略和趨勢,企業可以使其數據基礎設施面向未來,並確保其數據倉庫滿足不斷變化的分析需求。

