

介紹
數據湖是一個集中式存儲庫,允許組織大規模存儲結構化、半結構化和非結構化數據。與傳統數據倉庫不同,數據湖支持大數據分析、機器學習和實時處理。近年來,數據湖倉一體(一種結合了數據湖和數據倉庫優點的混合方法)的發展進一步增強了數據管理功能。本指南概述了設計、構建和維護數據湖的最佳實踐,以及數據湖開發的實際用例和現代趨勢。
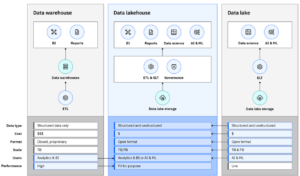
1. 了解數據湖架構
典型的數據湖由多個層組成,以確保高效的數據存儲、處理和訪問控制。這些層次包括:
- 原始數據攝取層:從IoT設備、應用程式、日誌和外部 API 等各種來源收集數據。
- 處理層:支援使用 Apache Spark 和 AWS Glue 等框架進行數據清理、轉換和索引。
- 存儲層:使用可擴展且經濟高效的存儲解決方案,如 Amazon S3、Azure Data Lake 或 Google Cloud Storage。
- 元數據和治理層:實施架構管理、編目(例如 AWS Glue Data Catalog)和數據沿襲跟蹤。
- 消耗層:允許通過 BI 工具、機器學習模型和 SQL 查詢引擎(如 Presto 或 Databricks)進行訪問。
架構選擇的關鍵考慮因素
- 基於雲的與本地:雲存儲提供可擴展性和彈性,而本地解決方案為受監管的行業提供更高的安全性。
- 開源與專有:Apache Hadoop、Apache Iceberg 和 Delta Lake 等技術支持開源開發,而 Snowflake 和 Databricks 則提供託管服務。
- Schema-on-Read 與 Schema-on-Write:數據湖使用讀時模式方法,可實現靈活的數據探索。
使用案例:零售公司使用基於 AWS 的數據湖來提取即時客戶交易和產品庫存數據,用於個人化營銷活動。
__________________________________________________________________________________________________________________
2. 構建數據湖的最佳實踐
2.1 定義業務目標和用例
- 明確定義數據湖的用途,例如 AI 模型訓練、客戶分析或欺詐檢測。
- 與業務利益相關者保持一致,以確定數據源、預期輸出和集成點。
示例:金融服務公司構建了一個數據湖來集成信用評分數據,以便即時批准貸款。
2.2 數據攝取策略
- 支援使用 Kafka、AWS Kinesis 和 Apache Flink 等工具進行批量和即時提取。
- 根據性能需求建立 ETL(提取、轉換、載入)與 ELT(提取、載入、轉換)策略。
- 使用數據版本控制來跟蹤數據隨時間的變化。
使用案例:社交媒體平臺每天使用Apache Kafka將數十億次使用者互動流式傳輸到數據湖中,並近乎即時地處理見解。
2.3 數據治理和安全
- 實施基於角色的訪問控制 (RBAC) 和加密(例如 AWS IAM 策略、Azure RBAC)。
- 使用 Apache Atlas、AWS Glue 或 Collibra 實施數據編目。
- 確保遵守GDPR、HIPAA和CCPA法規。
示例:醫療保健供應商使用 AWS IAM 按部門限制患者數據訪問,並加密數據湖中的敏感記錄。
2.4 優化數據存儲和性能
- 使用 Apache Parquet 或 ORC 等列式儲存格式進行高效查詢。
- 應用數據分區和索引以加快訪問速度。
- 實施數據保留和存檔的生命週期策略。
使用案例:某電信公司按區域和年份對客戶通話數據進行分區,將查詢執行時間縮短了 60%。
2.5 元數據管理和數據品質
- 自動標記元數據以更好地發現數據。
- 使用 Great Expectations 或 Deequ 實施數據分析和質量檢查。
- 跟蹤數據沿襲以保持轉換的透明度。
示例:製造公司使用 Databricks Delta Lake 來確保全球供應鏈記錄的數據一致性。
__________________________________________________________________________________________________________________
3. 數據湖倉一體:下一次演變
數據湖倉一體將數據湖的靈活性與數據倉庫的結構化查詢功能相結合。主要功能包括:
- ACID 事務:使用 Delta Lake、Apache Hudi 或 Iceberg 確保可靠性。
- 統一存儲和計算:通過允許對原始數據進行直接 SQL 查詢來減少數據重複。
- BI 和 ML 支援:與機器學習工作流和 BI 控制面板無縫集成。
示例:製藥公司採用 Databricks 湖倉一體架構進行即時藥物研究分析,從而減少數據處理延遲。
__________________________________________________________________________________________________________________
4. 性能優化策略
4.1 緩存和查詢加速
- 使用 Presto、Trino 或 Apache Dremio 更快地查詢原始數據。
- 使用 AWS Redshift Spectrum 或 Snowflake 外部表實施數據湖緩存。
使用案例:物流供應商使用 Databricks Delta Aching 加速供應鏈查詢,將報告生成時間從幾小時縮短到幾分鐘。
4.2 數據分層和成本優化
- 將經常訪問的數據存儲在熱存儲(例如,SSD 支援的 S3)中,同時將冷數據存檔在 Glacier 或 Azure Blob Archive 中。
- 使用自動擴展計算集群,根據工作負載需求優化成本。
示例:媒體流式處理服務通過將熱門視頻保留在高性能存儲中,同時存檔較舊的內容來平衡成本。
__________________________________________________________________________________________________________________
5. 主要挑戰和解決方案
5.1 數據沼澤和數據品質差
- 建立數據分類策略以避免非託管存儲庫。
- 使用數據沿襲跟蹤來維護版本控制。
5.2 跨多雲環境管理安全性
- 使用聯合身份管理實施零信任架構。
- 使用多雲加密密鑰保護 AWS、Azure 和 GCP 中的數據。
5.3 確保用戶採用
- 提供自助式分析工具,如 Tableau、Power BI 和 Looker。
- 使用 Trino 或 Snowflake 培訓團隊使用 SQL on-data-lake 功能。
__________________________________________________________________________________________________________________
6. 數據湖實施路線圖(12-18 個月)
第1階段:規劃(0-3個月)
- 定義目標和預期結果。
- 選擇雲供應商和存儲架構。
第 2 階段:數據攝取和存儲(3-6 個月)
- 開發批量和流式攝取管道。
- 應用元數據標記和監管策略。
第 3 階段:處理和優化(6-12 個月)
- 實施索引、緩存和查詢加速。
- 設置數據安全性和合規性框架。
第 4 階段:分析和 AI/ML 集成(12-18 個月)
- 為業務使用者啟用 BI 工具存取許可權。
- 與 AI/ML 模型整合以進行預測分析。
__________________________________________________________________________________________________________________
結論
構建現代數據湖需要戰略規劃、治理和性能優化,以釋放其全部潛力。數據湖倉一體的興起進一步簡化了對原始數據運行結構化查詢的能力,同時支援可擴展的分析和機器學習工作流。
通過遵循這些最佳實踐,組織可以創建一個高效、安全且面向未來的數據湖,以支援 AI 驅動型世界中的高級分析和商業智慧。

