

Introduction
A data lake is a centralized repository that allows organizations to store structured, semi-structured, and unstructured data at scale. Unlike traditional data warehouses, data lakes support big data analytics, machine learning, and real-time processing. In recent years, the evolution of the data lakehouse—a hybrid approach combining the best of data lakes and data warehouses—has further enhanced data management capabilities. This guide outlines the best practices for designing, building, and maintaining a data lake, along with real-world use cases and modern trends in data lake development.
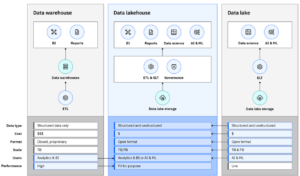
1. Understanding Data Lake Architecture
A typical data lake consists of multiple layers to ensure efficient data storage, processing, and access control. These layers include:
- Raw Data Ingestion Layer: Collects data from diverse sources such as IoT devices, applications, logs, and external APIs.
- Processing Layer: Supports data cleansing, transformation, and indexing using frameworks like Apache Spark and AWS Glue.
- Storage Layer: Uses scalable and cost-effective storage solutions like Amazon S3, Azure Data Lake, or Google Cloud Storage.
- Metadata and Governance Layer: Implements schema management, cataloging (e.g., AWS Glue Data Catalog), and data lineage tracking.
- Consumption Layer: Allows access via BI tools, machine learning models, and SQL query engines like Presto or Databricks.
Key Considerations for Architecture Selection
- Cloud-Based vs. On-Premise: Cloud storage provides scalability and elasticity, while on-premise solutions offer greater security for regulated industries.
- Open-Source vs. Proprietary: Technologies like Apache Hadoop, Apache Iceberg, and Delta Lake support open-source development, while Snowflake and Databricks provide managed services.
- Schema-on-Read vs. Schema-on-Write: Data lakes use a schema-on-read approach, enabling flexible data exploration.
Use Case: A retail company uses an AWS-based data lake to ingest real-time customer transactions and product inventory data for personalized marketing campaigns.
__________________________________________________________________________________________________________________
2. Best Practices for Building a Data Lake
2.1 Define Business Objectives and Use Cases
- Clearly define the purpose of the data lake, such as AI model training, customer analytics, or fraud detection.
- Align with business stakeholders to determine data sources, expected outputs, and integration points.
Example: A financial services firm builds a data lake to integrate credit scoring data for real-time loan approvals.
2.2 Data Ingestion Strategy
- Support batch and real-time ingestion using tools like Kafka, AWS Kinesis, and Apache Flink.
- Establish an ETL (Extract, Transform, Load) vs. ELT (Extract, Load, Transform) strategy based on performance needs.
- Use data versioning to track data changes over time.
Use Case: A social media platform streams billions of user interactions per day into a data lake using Apache Kafka and processes insights in near real-time.
2.3 Data Governance and Security
- Implement role-based access control (RBAC) and encryption (e.g., AWS IAM policies, Azure RBAC).
- Enforce data cataloging using Apache Atlas, AWS Glue, or Collibra.
- Ensure compliance with GDPR, HIPAA, and CCPA regulations.
Example: A healthcare provider restricts patient data access by department using AWS IAM and encrypts sensitive records in the data lake.
2.4 Optimize Data Storage and Performance
- Use columnar storage formats like Apache Parquet or ORC for efficient querying.
- Apply data partitioning and indexing to speed up access.
- Implement lifecycle policies for data retention and archival.
Use Case: A telecom company partitions customer call data by region and year, reducing query execution time by 60%.
2.5 Metadata Management and Data Quality
- Automate metadata tagging for better data discovery.
- Implement data profiling and quality checks using Great Expectations or Deequ.
- Track data lineage to maintain transparency in transformations.
Example: A manufacturing firm uses Databricks Delta Lake to ensure data consistency across global supply chain records.
__________________________________________________________________________________________________________________
3. Data Lakehouse: The Next Evolution
A data lakehouse merges the flexibility of a data lake with the structured querying capabilities of a data warehouse. Key features include:
- ACID Transactions: Ensures reliability using Delta Lake, Apache Hudi, or Iceberg.
- Unified Storage and Compute: Reduces data duplication by allowing direct SQL queries on raw data.
- BI and ML Support: Seamlessly integrates with machine learning workflows and BI dashboards.
Example: A pharmaceutical company adopts a Databricks lakehouse architecture for real-time drug research analytics, reducing data processing delays.
__________________________________________________________________________________________________________________
4. Performance Optimization Strategies
4.1 Caching and Query Acceleration
- Use Presto, Trino, or Apache Dremio for faster queries on raw data.
- Implement data lake caching using AWS Redshift Spectrum or Snowflake External Tables.
Use Case: A logistics provider accelerates supply chain queries using Databricks Delta Caching, reducing report generation time from hours to minutes.
4.2 Data Tiering and Cost Optimization
- Store frequently accessed data in hot storage (e.g., SSD-backed S3), while archiving cold data in Glacier or Azure Blob Archive.
- Use auto-scaling compute clusters to optimize costs based on workload demand.
Example: A media streaming service balances cost by keeping trending videos in high-performance storage while archiving older content.
__________________________________________________________________________________________________________________
5. Key Challenges and Solutions
5.1 Data Swamps and Poor Data Quality
- Establish data classification policies to avoid an unmanaged repository.
- Use data lineage tracking to maintain version control.
5.2 Managing Security Across Multi-Cloud Environments
- Implement zero-trust architecture with federated identity management.
- Use multi-cloud encryption keys to secure data across AWS, Azure, and GCP.
5.3 Ensuring User Adoption
- Provide self-service analytics tools like Tableau, Power BI, and Looker.
- Train teams on SQL-on-data-lake capabilities using Trino or Snowflake.
__________________________________________________________________________________________________________________
6. Data Lake Implementation Roadmap (12-18 Months)
Phase 1: Planning (0-3 Months)
- Define objectives and expected outcomes.
- Choose cloud providers and storage architecture.
Phase 2: Data Ingestion and Storage (3-6 Months)
- Develop batch and streaming ingestion pipelines.
- Apply metadata tagging and governance policies.
Phase 3: Processing and Optimization (6-12 Months)
- Implement indexing, caching, and query acceleration.
- Set up data security and compliance frameworks.
Phase 4: Analytics and AI/ML Integration (12-18 Months)
- Enable BI tool access for business users.
- Integrate with AI/ML models for predictive analytics.
__________________________________________________________________________________________________________________
Conclusion
Building a modern data lake requires strategic planning, governance, and performance optimization to unlock its full potential. The rise of data lakehouses has further streamlined the ability to run structured queries on raw data while supporting scalable analytics and machine learning workflows.
By following these best practices, organizations can create an efficient, secure, and future-proof data lake that supports advanced analytics and business intelligence in the AI-driven world.

